GPT-4 Vision: How to use LangChain with Multimodal AI to Analyze Images in Financial Reports

Chat with data
View ChannelAbout
Learn how to build reliable AI agents and LLM applications without the technical jargon. Videos created by Mayo: Twitter- @mayowaoshin
Latest Posts


Video Description
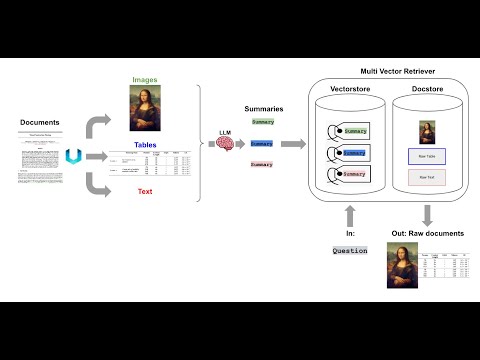
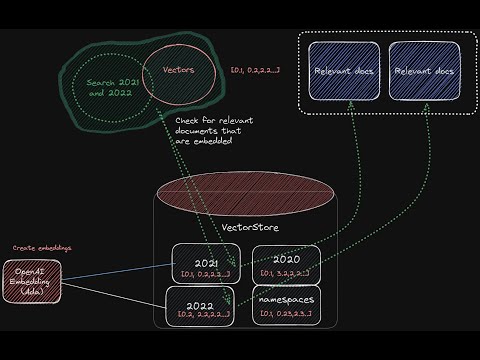
In this video, LangChainAI Engineer Lance Martin, delivers a workshop with Mayo Oshin on how to question-answer documents that contain diverse data types (images, text, tables) using GPT-4 with Vision and LangChain. During the workshop, Lance Martin shares a novel strategy that utilises RAG with LangChain to analyse financial reports that contain images. First, we create summaries of images, texts and tables. Then we embed these summaries in a vectorstore with reference to the original images, texts and tables. When a user makes a request, we retrieve relevant embedded summaries and pass raw images and text chunks to a multimodal LLM for answer synthesis. ----------------------- Workshop links:- slides: https://docs.google.com/presentation/d/1EJqIvYGbF5IGHX7orXaUSKVN3PVbQh7kOP7m5BEoyKQ/edit?usp=sharing Colab notebook: https://github.com/langchain-ai/langchain/blob/master/cookbook/Multi_modal_RAG.ipynb Chat with data links:- Twitter: https://twitter.com/mayowaoshin Website: https://www.mayooshin.com/ Send a tip to support the channel: https://ko-fi.com/mayochatdata Timestamps: 00:38 Demo of financial report 03:00 Multimodal architecture 17:30 Codebase walkthrough 31:35 Evaluating results using LangSmith 39:25 Showcasing results 41:25 Multimodal RAG problems and solutions #openai #gpt #finance #investing #langchain
Boost Your Financial Analysis
AI-recommended products based on this video

Firefly Variety 8 Pack - Fire Starter Accessory for Swiss Army Victorinox Knives (Neon Green-Yellow Glow)

9-in-1 5000A 150PSI Car Battery Booster Jump Starter with Air Compressor (All Gas/9L Diesel), Portable Car Battery Booster Pack, Safe Durable Car Jump Starter with Extended Jumper Cables, Glove, Light

Premium Feminine PH Balance Gummies for Women's Health,Vaginal Sugar Free Probiotics for Immune Support,Hawaiian Pineapple Gummies,60 Count
