Python Libraries to Extract Tables from PDFs

About
No channel description available.
Latest Posts


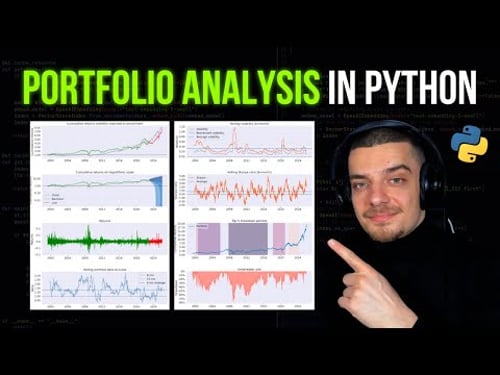

Video Description
In this video we compare different packages and strategies for extracting tables from PDF documents in Python. LLMWhisperer: https://unstract.com/llmwhisperer/?utm_source=nn Unstract: https://unstract.com/?utm_source=nn Unstract GitHub: https://github.com/Zipstack/unstract Code: https://github.com/NeuralNine/youtube-tutorials/tree/main/PDF%20Table%20Extraction ◾◾◾◾◾◾◾◾◾◾◾◾◾◾◾◾◾ 📚 Programming Books & Merch 📚 🐍 The Python Bible Book: https://www.neuralnine.com/books/ 💻 The Algorithm Bible Book: https://www.neuralnine.com/books/ 👕 Programming Merch: https://www.neuralnine.com/shop 💼 Services 💼 💻 Freelancing & Tutoring: https://www.neuralnine.com/services 🌐 Social Media & Contact 🌐 📱 Website: https://www.neuralnine.com/ 📷 Instagram: https://www.instagram.com/neuralnine 🐦 Twitter: https://twitter.com/neuralnine 🤵 LinkedIn: https://www.linkedin.com/company/neuralnine/ 📁 GitHub: https://github.com/NeuralNine 🎙 Discord: https://discord.gg/JU4xr8U3dm Timestamps: (0:00) Intro (0:23) PDF Documents (2:43) Camelot (7:46) Tabula (10:55) PDFPlumber (17:16) LLMWhisperer (23:32) PyPDF2 (26:40) Unstract
You May Also Like













Effortless PDF Table Extraction Tools
AI-recommended products based on this video
Blackhead Remover Vacuum - Pore Cleaner and Blackhead Extractor with 3 Adjustable Suction Levels, 5 Probes - Pore Vacuum Kit for Women&Men (Pearl White)

2025 New Screw-Top Lemon Squeezer,Fast Juicing, Portable Manual Citrus Juicer, Orange Extractor with Lid, Squeeze Lime for Cocktails, Drinks (yellow and green)
