The Era of 1-bit LLMs by Microsoft | AI Paper Explained


AI Papers Academy
@aipapersacademyAbout
Simplifying AI Papers
Latest Posts




Video Description
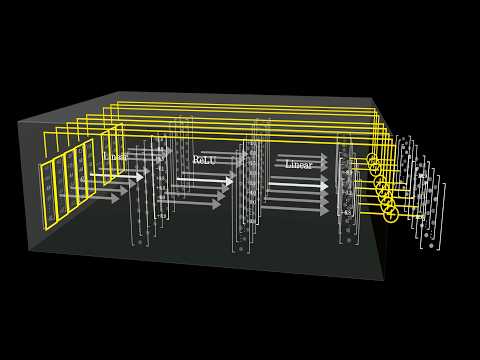
In this video we dive into a recent research paper by Microsoft: "The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits". This paper introduce an interesting and exciting architecture for large language models, called BitNet b1.58, which significantly reduces LLMs memory consumption, and speeds-up LLMs inference latency. All of that, while showing promising results, that do not fall from a comparable LLaMA model! Large language models quantization is already tackling the same problem, and we'll explain the benefits of BitNet b1.58 comparing to common quantization techniques. BitNet b1.58 is an improvement for the BitNet model presented few months ago. BitNet b1.58 paper - https://arxiv.org/abs/2402.17764 BitNet paper - https://arxiv.org/abs/2310.11453 Blog post - https://aipapersacademy.com/the-era-of-1-bit-llms/ ----------------------------------------------------------------------------------------------- ✉️ Join the newsletter - https://aipapersacademy.com/newsletter/ 👍 Please like & subscribe if you enjoy this content Become a patron - https://www.patreon.com/aipapersacademy We use VideoScribe to edit our videos - https://tidd.ly/44TZEiX ----------------------------------------------------------------------------------------------- Chapters: 0:00 Paper Introduction 0:55 Quantization 1:31 Introducing BitNet b1.58 2:55 BitNet b1.58 Benefits 4:01 BitNet b1.58 Architecture 4:46 Results








![The moment we stopped understanding AI [AlexNet]](https://imgz.pc97.com/?width=500&fit=cover&image=https://i.ytimg.com/vi/UZDiGooFs54/hqdefault.jpg)









Kefir Making Starter Kit
AI-recommended products based on this video

Candle Warmer Lamp with Timer - Adjustable Height Electric Candle Warmer Lamp with Dimmer, Flower Glass Shade Wax Melt Warmer with Wood Base, Dimmable Halogen Candle Warmer for Jar Candles Home Decor

Star Wars Owala FreeSip Insulated Stainless Steel Water Bottle with Straw, BPA-Free Sports Water Bottle, Great for Travel, 32 Oz, Darth Vader

Star Wars Owala FreeSip Insulated Stainless Steel Water Bottle with Straw, BPA-Free Sports Water Bottle, Great for Travel, 32 Oz, GroGu

2PC Multi-Functional Vegetable Peeler for Kitchen,Vegetable Peeler Wooden Handle,2-in-1 Stainless Steel Fruit & Vegetable Peelers with Bottle Opener for Potato Pineapple

Aquoxis Pressure Washer, Aquoxis Pressure Washer Gun, Durable Stainless Steel, 360° Rotating for Three Spray Modes, Fast & Portable, and Time-Efficient, Universal Compatibility (1PCS+Foaming Pitcher)

Portable 2-Wheel Oxygen Cylinder Cart, 23.5cm Diameter Oxygen Tank Trolley with Handle, Rolling Gas Bottle Storage Rack for Home Use, Lightweight Oxygen Tank Transporter
![Lamicall Bike Water Bottle Holder - [Tracker Storage] [for Handlebar & Frame] Bike Cup Holder, Bicycle Drink Cage, Cycling Bike Water Bottle Cage with Screws Tool, for 2.28-3.39" Diameter Bottles](https://m.media-amazon.com/images/I/61ZWYR84UXL._AC_UL960_FMwebp_QL65_.jpg)
Lamicall Bike Water Bottle Holder - [Tracker Storage] [for Handlebar & Frame] Bike Cup Holder, Bicycle Drink Cage, Cycling Bike Water Bottle Cage with Screws Tool, for 2.28-3.39" Diameter Bottles
